 مخصوص اعضای ویژه
مخصوص اعضای ویژه 



SQL، مثل: Oracle، MySQL، Microsoft SQL Server، PostgreSQL
NoSQL، مثل: MongoDB، Redis، Casandra
SQL پایگاه داده رابطهای و NoSQL پایگاه داده غیررابطهای است. در این مقاله مزایا و معایب 10 مورد از بهترین پایگاه دادهها را بررسی میکنیم. بنابراین میتوانید هر کدام که برای برنامهیتان مناسبتر است را انتخاب کنید.در اینجا لیستی از پایگاه دادهها برای سال 2018 وجود دارد.
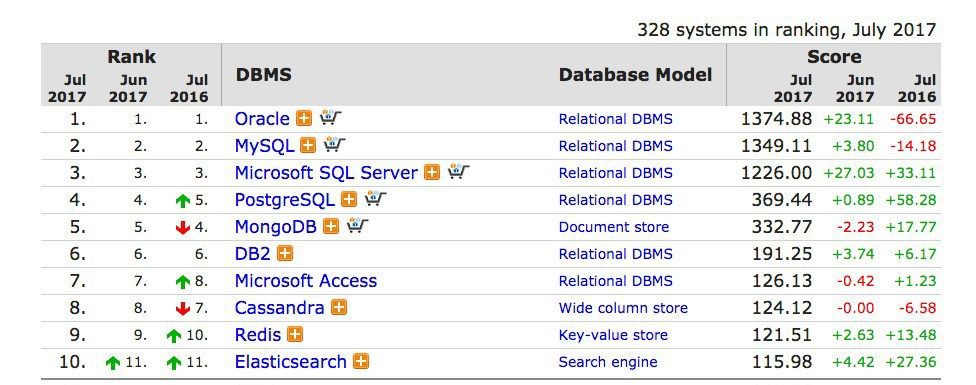
محبوبترین پایگاه دادهها در میان برنامهنویسان
Oracle
MySQL
Microsoft SQL Server
PostgreSQL
MongoDB
DB2
Microsoft Access
Cassandra
Elasticsearch
1. Oracle
بله، اوراکل پادشاه محبوبترین پایگاه دادهها است. چرا؟ این پایگاه داده واقعا در میان توسعهدهندگان معروف است، به آسانی میتوان از آن استفاده کرد، اسناد به خوبی نوشته میشوند، ویژگیهای جدیدش شگفتانگیز است (JSON از SQL، پشتیبانی از اسامی طولانی، بهبود تگ لیست و غیره).
آخرین ورژن پایگاه داده اوراکل c12 است.
2. MySQL
شرکتها میتوانند با استفاده از سرورهای عمومی رایگان شروع به کار کرده و بعدا آن را به نسخه تجاری ارتقاء دهند.
روی لینوکس، ویندوز، OSX و FreeBSD و Solaris اجرا میشود.
دارای رابط کاربری گرافیکی بصری برای طراحی جداول پایگاه داده میباشد.
با توجه به open-source بودنش، یک بانک بزرگ از آموزشها و اطلاعات دارد که در دسترس شما قرار میگیرد تا مسائل را شروع کرده و حل کنید.
از پارتیشنبندی و رونوشت پشتیبانی میکند، همچنین برای Xpath و ذخیرهسازی پروسیجرها، triggerها و viewها میباشد.
3. Microsoft SQL Server
به طور گسترده برای DBMS تجاری استفاده میشود.
محدود به ویندوز است، اما اگر شرکت شما بیشتر از محصولات مایکروسافت استفاده میکند، این یک مزیت محسوب میشود.
4. PostgreSQL
پایگاه داده شیء-رابطه مقیاسپذیر است.
بر روی لینوکس، ویندوز، OSX و چندین سیستم دیگر اجرا میشود.
از tablespaceها، stored procedureها، joinها، viewها، triggerها و غیره پشتیبانی میکند.
5. MongoDB
محبوبترین پایگاه داده NoSQL است. با این وجود برخی خواص SQL مثل کوئری و ایندکس را حفظ میکند.
طیف گستردهای از زبانهای برنامه نویسی مثل Scala، Groovy، Clojure و Java را قدرتمند میسازد.
عملکرد بالایی در پایگاه دادههای بسیار بزرگ دارد.
برای کوئریهای داینامیک و تعریف ایندکسها بهترین است.
لینوکس، ویندوز و OSX را قدرتمند میسازد، اما اندازه پایگاه داده روی سیستمهای 32 بیتی به 2.5 GB محدود میشود.
6. DB 2
پاسخ IBM به g11 اوراکل است، در host و نسخههای ویندوز/لینوکس قابل دسترس میباشد.
بر روی لینوکس، یونیکس، ویندوز و رایانههای بزرگ اجرا میشود.
برای محیط هاست IBM ایدهآل است.
از هر دو مدل SQL و NoSQL پشتیبانی میکند.
7. Microsoft Access
برای پایگاه دادههای رابطهای مورد استفاده قرار میگیرد.
مانند Microsoft SQL Server، به ویندوز محدود میشود.
ایدهآل برای شروع با تحلیل ترافیک است، اما عملکرد آن برای پروژههای با مقیاس بزرگ طراحی نشده است.
زبانهای برنامهنویسی محدود شده به C، #C، ++C، Java، VBA و Visual Rudimental.NET را قدرتمند میسازد.
8. Cassandra
پایگاه داده NoSQL با دسترسیپذیری بالا است.
برای ذخیرهسازی مجموعه دادههای بسیار بزرگ با رابط کاربری سازنده میباشد.
در بانکداری، امور مالی و ثبت محبوب است، به علاوه توسط فیسبوک و توییتر هم استفاده میشود.
ویندوز، لینوکس و OSX، همچنین زبانهای متعدد دیگری را قدرتمند میسازد.
در هنگام استفاده با Hadoop، Map/reduce امکانپذیر است.
9. Redis
این پایگاه داده open-source، شبکهای و in-recollection استکه پایداری کلیدها به صورت انتخابی ذخیره میشود.
اطلاعات در این پایگاه داده به صورت کلید/مقدار ذخیره میشوند.
Redis معمولا روی پلتفرمهای IaaS و PaaS مثل Amazon Web Accommodations، Rackspace یا Heroku قرار میگیرد.
بسیاری از زبانها اتصال داده Redis دارند، ازجمله ActionScript, C, C++, C#, Clojure, Prevalent Lisp, Dart, Erlang, Go, Haskell, Haxe, Io, Java, JavaScript (Node.js), Lua, Objective-C, Perl, PHP, Pristine Data, Python, R, Ruby, Scala, Smalltalk and Tcl
10. Elasticsearch
Elasticsearch یک موتور جستجوی open-source، به طور گسترده قابل توزیع، به راحتی قابل مقیاس میباشد. با استفاده از یک API گسترده و دقیق قابل دسترس است. میتواند جستجوهای بسیار سریع که از برنامههای یابنده اطلاعات شما پشتیبانی میکند را انجام دهد.
در Elasticsearch این عملیات ظریف و اغلب متمرکز به طور خودکار و غیر قابل مشاهده رخ میدهند:
تقسیمبندی اسناد در میان ترتیبی از مقیاسها (shard) یا نگهدارندههای متمایز.
در یک کلاستر(cluster) چند گرهای،اسناد برای shardهایی که در میان تمام گرهها قرار دارند، توزیع میشوند.
تعادلسازی بین Shardهای تمام گرهها در یک کلاستر تا ایندکس کردن و لود جستجوها به طور مساوی مدیریت شوند.
تکرار و تکثیر هر shard برای ارائه افزونگی داده و failover
درخواست مسیریابی از هر گره در کلاستر برای گرههای خاص حاوی دادههای خاص مورد نیاز شما
افزودن و ادغام گرههای جدید مانند وقتی که می خواهید اندازه کلاستر را افزایش دهید.
توزیع مجدد Shardها برای بازیابی خودکار گرههایی که از دست رفتهاند.
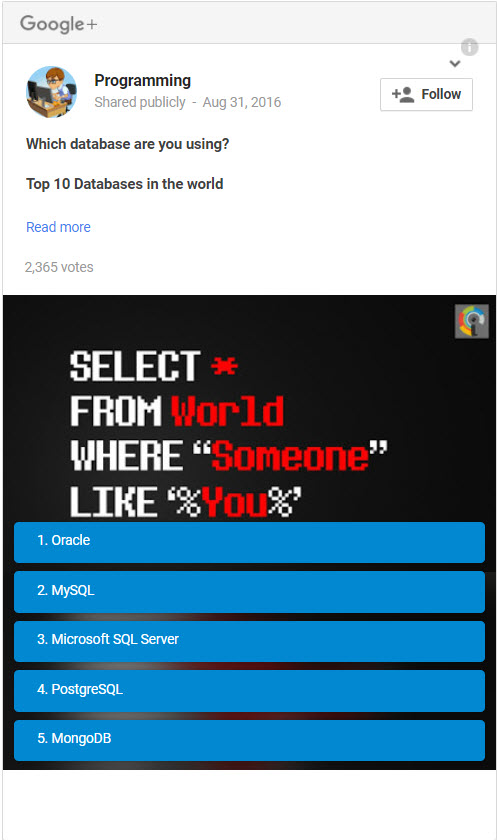
ما اخیرا یک نظرسنجی از برنامهنویسان مختلف در گوگل پلاس و رسانههای اجتماعی گرفتهایم. در این نظرسنجی همه پایگاه دادههای SQL و NoSQL را بررسی کردیم. در تصویر زیر میتوانید محبوبتری پایگاه دادهها در سال 2018 را ببینید.



نظرات کاربران در رابطه با این دوره